
线程池和连接数配置
前言
在使用tomcat时,经常会遇到连接数、线程数之类的配置问题,要真正理解这些概念,必须先了解Tomcat的连接器(Connector)。
Connector的主要功能是接收连接请求,创建Request和Response对象用于和请求端交换数据;然后分配线程让Engine(也就是Servlet容器)来处理这个请求,并把产生的Request和Response对象传给Engine。当Engine处理完请求后,也会通过Connector将响应返回给客户端。可以说,Servlet容器处理请求,是需要Connector进行调度和控制的,Connector是Tomcat处理请求的主干,因此Connector的配置和使用对Tomcat的性能有着重要的影响。
根据协议的不同,Connector可以分为HTTP Connector、AJP Connector等,本文只讨论HTTP Connector。
Connector中的协议
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />Connector在处理HTTP请求时,会使用不同的protocol。不同的Tomcat版本支持的protocol不同,其中最典型的protocol包括BIO、NIO和APR(Tomcat7中支持这3种,Tomcat8增加了对NIO2的支持,而到了Tomcat 8.5和Tomcat 9.0,则去掉了对BIO的支持)。
protocol取值及对应的协议如下:
HTTP/1.1:默认值,使用的协议与Tomcat版本有关:在Tomcat7中,自动选取使用BIO或APR(如果找到APR需要的本地库,则使用APR,否则使用BIO);
在Tomcat8中,自动选取使用NIO或APR(如果找到APR需要的本地库,则使用APR,否则使用NIO)。
org.apache.coyote.http11.Http11Protocol,即BIOTomcat 7~Tomcat 8支持
org.apache.coyote.http11.Http11NioProtocol,即NIOTomcat 7以上支持
org.apache.coyote.http11.Http11Nio2Protocol,即NIO2Tomcat 8以上支持
org.apache.coyote.http11.Http11AprProtocol,即APRTomcat 7以上支持
APR是Apache Portable Runtime,是Apache可移植运行库,利用本地库可以实现高可扩展性、高性能;该协议是在Tomcat上运行高并发应用的首选模式,但是需要安装apr、apr-utils、tomcat-native等包。
无论是BIO,还是NIO,Connector处理请求的大致流程是一样的:①在accept队列中接收连接(当客户端向服务器发送请求时,如果客户端与OS完成三次握手建立了连接,则OS将该连接放入accept队列);②在连接中获取请求的数据,生成request;调用servlet容器处理请求;③返回response。
连接是TCP层面的(传输层),对应socket;请求是HTTP层面的(应用层),必须依赖于TCP的连接实现;一个TCP连接中可能传输多个HTTP请求。
在BIO实现的Connector中,处理请求的主要实体是JIoEndpoint对象。JIoEndpoint维护了Acceptor和Worker:Acceptor接收socket,然后从Worker线程池中找出空闲的线程处理socket,如果worker线程池没有空闲线程,则Acceptor将阻塞。其中Worker是Tomcat自带的线程池,如果通过<Executor>配置了其他线程池,原理与Worker类似。
在NIO实现的Connector中,处理请求的主要实体是NIoEndpoint对象。NIoEndpoint中除了包含Acceptor和Worker外,还是用了Poller,处理流程如下图所示:
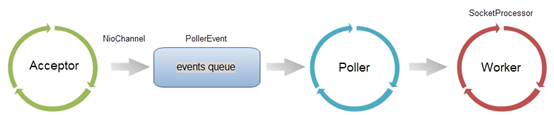
Acceptor接收socket后,不是直接使用Worker中的线程处理请求,而是先将请求发送给了Poller,而Poller是实现NIO的关键。Acceptor向Poller发送请求通过队列实现,使用了典型的生产者-消费者模式。在Poller中,维护了一个Selector对象;当Poller从队列中取出socket后,注册到该Selector中;然后通过遍历Selector,找出其中可读的socket,并使用Worker中的线程处理相应请求。与BIO类似,Worker也可以被自定义的线程池代替。
通过上述过程可以看出,在NIoEndpoint处理请求的过程中,无论是Acceptor接收socket,还是线程处理请求,使用的仍然是阻塞方式;但在“读取socket并交给Worker中的线程”的这个过程中,使用非阻塞的NIO实现,这是NIO模式与BIO模式的最主要区别(其他区别对性能影响较小,暂时略去不提)。而这个区别,在并发量较大的情形下可以带来Tomcat效率的显著提升:目前大多数HTTP请求使用的是长连接(HTTP/1.1默认keep-alive为true),而长连接意味着,一个TCP的socket在当前请求结束后,如果没有新的请求到来,socket不会立马释放,而是等timeout后再释放。如果使用BIO,“读取socket并交给Worker中的线程”这个过程是阻塞的,也就意味着在socket等待下一个请求或等待释放的过程中,处理这个socket的工作线程会一直被占用,无法释放;因此Tomcat可以同时处理的socket数目不能超过最大线程数,性能受到了极大限制。而使用NIO,“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。
TODO: NIO2与NIO相比的改进之处:
Connector的配置
再回顾一下Tomcat处理请求的过程:
①在accept队列中接收连接(当客户端向服务器发送请求时,如果客户端与OS完成三次握手建立了连接,则OS将该连接放入accept队列);
②在连接中获取请求的数据,生成request;
③调用servlet容器处理请求;
④返回response。
相对应的,Connector中的几个参数功能如下:
acceptCount:accept队列的长度;当accept队列中连接的个数达到acceptCount时,队列满,进来的请求一律被拒绝。默认值是100。maxConnections:Tomcat在任意时刻接收和处理的最大连接数。当Tomcat接收的连接数达到maxConnections时,Acceptor线程不会读取accept队列中的连接;这时accept队列中的线程会一直阻塞着,直到Tomcat接收的连接数小于maxConnections。如果设置为-1,则连接数不受限制。默认值与连接器使用的协议有关:NIO的默认值是10000,APR/native的默认值是8192,而BIO的默认值为maxThreads(如果配置了Executor,则默认值是Executor的maxThreads)。在windows下,APR/native的maxConnections值会自动调整为设置值以下最大的1024的整数倍;如设置为2000,则最大值实际是1024。maxThreads:请求处理线程的最大数量。默认值是200(Tomcat7和8都是)。如果该Connector绑定了Executor,这个值会被忽略,因为该Connector将使用绑定的Executor,而不是内置的线程池来执行任务。maxThreads规定的是最大的线程数目,并不是实际running的CPU数量;实际上,maxThreads的大小比CPU核心数量要大得多。这是因为,处理请求的线程真正用于计算的时间可能很少,大多数时间可能在阻塞,如等待数据库返回数据、等待硬盘读写数据等。因此,在某一时刻,只有少数的线程真正的在使用物理CPU,大多数线程都在等待;因此线程数远大于物理核心数才是合理的。
(1)maxThreads的设置既与应用的特点有关,也与服务器的CPU核心数量有关。通过前面介绍可以知道,maxThreads数量应该远大于CPU核心数量;而且CPU核心数越大,maxThreads应该越大;应用中CPU越不密集(IO越密集),maxThreads应该越大,以便能够充分利用CPU。当然,maxThreads的值并不是越大越好,如果maxThreads过大,那么CPU会花费大量的时间用于线程的切换,整体效率会降低。
(2)maxConnections的设置与Tomcat的运行模式有关。如果tomcat使用的是BIO,那么maxConnections的值应该与maxThreads一致;如果tomcat使用的是NIO,那么类似于Tomcat的默认值,maxConnections值应该远大于maxThreads。
(3)虽然tomcat同时可以处理的连接数目是maxConnections,但服务器中可以同时接收的连接数为maxConnections+acceptCount 。acceptCount的设置,与应用在连接过高情况下希望做出什么反应有关系。如果设置过大,后面进入的请求等待时间会很长;如果设置过小,后面进入的请求立马返回connection refused。
线程池Executor
Executor元素代表Tomcat中的线程池,可以由其他组件共享使用;要使用该线程池,组件需要通过executor属性指定该线程池。
Executor是Service元素的内嵌元素。一般来说,使用线程池的是Connector组件;为了使Connector能使用线程池,Executor元素应该放在Connector前面。
Executor的主要属性包括:
name:该线程池的标记
maxThreads:线程池中最大活跃线程数,默认值200(Tomcat7和8都是)
minSpareThreads:线程池中保持的最小线程数,最小值是25
maxIdleTime:线程空闲的最大时间,当空闲超过该值时关闭线程(除非线程数小于minSpareThreads),单位是ms,默认值60000(1分钟)
daemon:是否后台线程,默认值true
threadPriority:线程优先级,默认值5
namePrefix:线程名字的前缀,线程池中线程名字为:namePrefix+线程编号
查看当前的连接数和线程数
查看服务器的状态,大致分为两种方案:(1)使用现成的工具,(2)直接使用Linux的命令查看。
现成的工具,如JDK自带的jconsole工具可以方便的查看线程信息(此外还可以查看CPU、内存、类、JVM基本信息等),Tomcat自带的manager,收费工具New Relic等。下图是jconsole查看线程信息的界面:
下面说一下如何通过Linux命令行,查看服务器中的连接数和线程数。
1、查看当前连接数
假设Tomcat接收http请求的端口是8083,则可以使用如下语句查看连接情况:
2、查看当前线程数
内容来源
以下为文中提到的参考文献。
Tomcat maxThreads maxConnections acceptCount参数说明
Last updated